This is Part 3 of my Data engineering in the European cloud series. In Part 1 I described my plan for creating a data lakehouse in the European cloud. In Part 2 I got a data lakehouse working at the French cloud provider Scaleway. It was a good start, but you know how Read more
This is Part 2 in a series where I try to create a data engineering environment in the European cloud. In Part 1 I described my plan for creating a data lakehouse in the European cloud. Now it’s time to get our hands dirty. We’re going to do this in the Scaleway cloud.
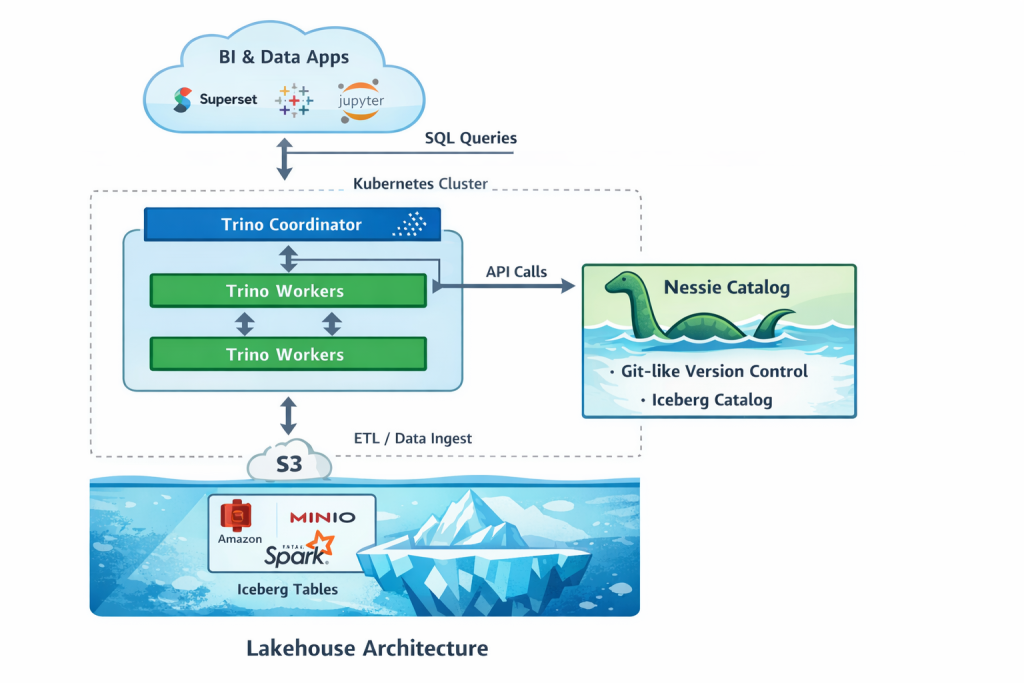
The architecture
To get this data lakehouse running we will create a Kubernetes cluster and object storage for our data storage. In Kubernetes we can run containerised applications that will run our data lakehouse. I’ve consulted ChatGPT for this architecture. It had a better and more modern solution than I originally had in mind.
We’re going to use the Apache Iceberg open table format. This will allow us to create database like tables based on Parquet formatted files. Nessie will be the Iceberg data catalog (Hive Metastore was another option). It allows our data solutions to find the Iceberg tables and underlying Parquet files.
Trino will be the query engine. That will be the fastest way to get our first queries going.
And to be honest, when customers ask for advice on starting a new data engineering ecosystem, Azure Fabric and Databricks are on the top of my list.
But while it might be hard to switch from Office 365 to open source solutions (especially moving all your users to these unknown platforms), in the data engineering landscape there are so many widely adopted open source solutions. Solutions that end users rarely need to deal with directly. Couldn’t we run these products somewhere else? So I went on an investigation.