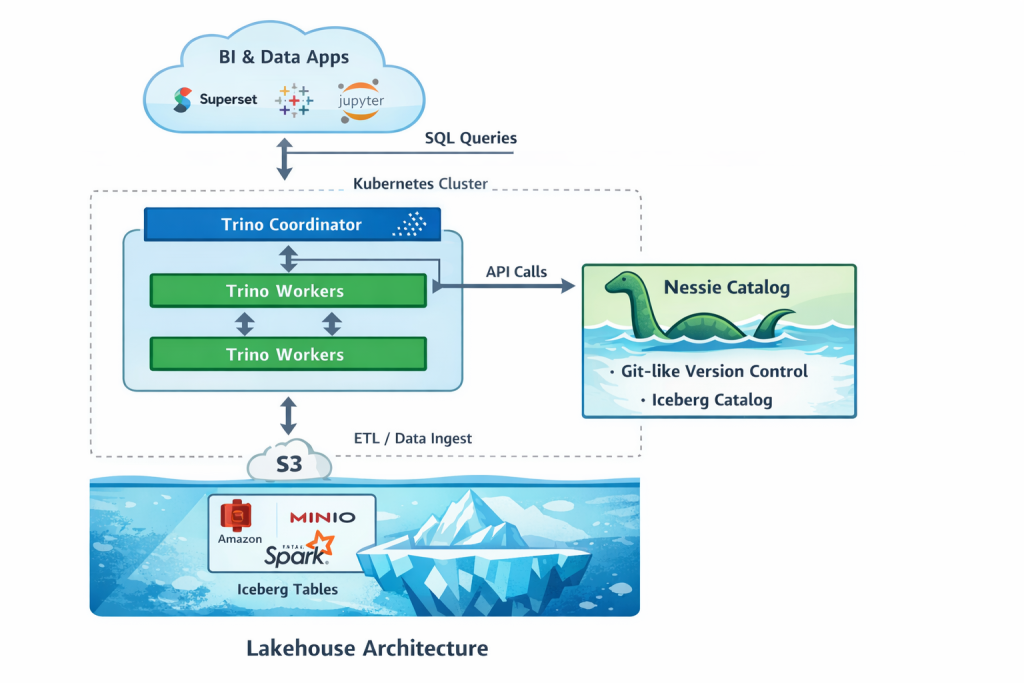
Data engineering
Data modelling – the detective work you need to do to understand your source data.
It is almost 9 years ago that I became a data engineer and I can honestly say my job is vastly different than what I thought it would be at the start. I still love what I do, but the reality is that data-product building is far more than just handling big data systems. Nine years ago though, I thought I would be kind of a Big Data DBA. I hadn’t given a lot of thought about the data modelling involved.
Gradually I learned that building data products takes quite a bit of forethought. And when you build data products you need to know your source data quite well.
(more…)