How it started
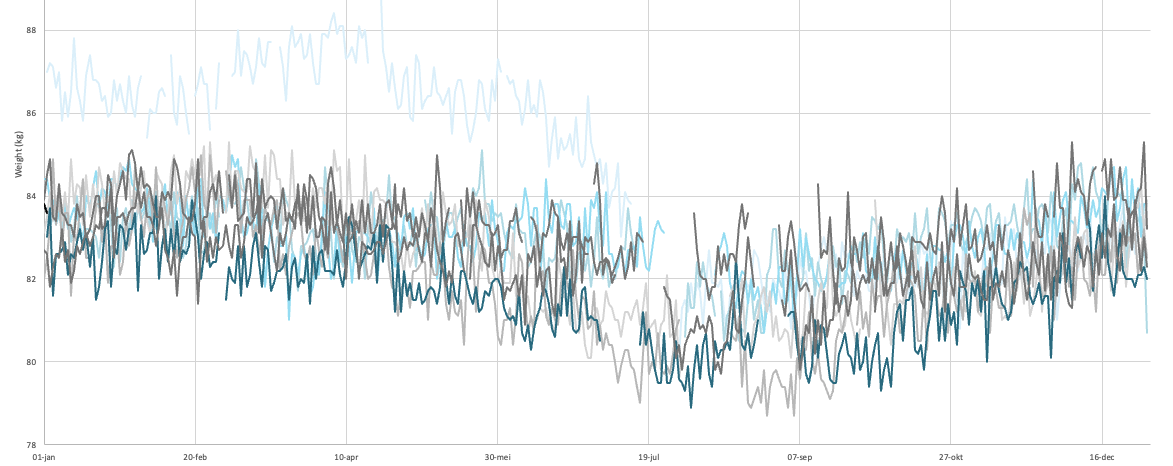
For several years I kept track of my weight and fat with a Soehnle Body Balance, which I bought in 2018. That worked quite well until I saw more and more these weird deviations. Take a look at the red line (fat percentage) in the graph below:

I’ve been training harder in the last 2 years, but according to the fat measurements I gained more fat, not less. And also, after a day of a long bike ride, the fat percentage would peak the next day, instead of getting lower. In the last few months I would regularly get fat percentage measurements of 30+%. And it was not like I was eating burgers, fries and ice cream everyday. It didn’t look like the fat measurements were very accurate anymore.
My new scale
I decided it was time for a new personal scale. After some deliberation I picked the Robi S11. It is a “Smart body composition scale” according to the brochure. It has a handheld device that measures your body fat (and a whole lot of other things) more accurately. It is similar to how my doctor measures my fat percentage during my half yearly checkup. And it was moderately priced.

Now this is one of those scales that has a Bluetooth connection. I’ve always had a healthy mistrust of sharing my health data with apps like these. Especially when the parent company is one Guandong Icomon Technology. Who knows where your data goes to and how securely it is stored?
I decided to give their Fitdays app a try anyway. I filled in the limited amount of personal details (and not all of them entirely accurate). And of course I didn’t give the app any more access to iPhone data than absolutely necessary. For what it’s worth.
The device does an impressive amount of measurements. It measures not just weight, fat, water and muscle tissue. It can do so per arm and leg. And somehow it also can measure bone mass and protein mass in your body. Not sure how accurate and scientific all this is though.
The app shows all these results. And then came the little matter of me wanting to copy all that data. Luckily the app has a “share” option. I was able to Airdrop that data to my MacBook. So I was excited… until I got said data. Because it was in the form of a jpeg file.

Your data, in jpeg form
You can’t copy the values. You can’t get the data in any other form. Good luck!
Good luck? Well we’ll see about that. I decided to summon the power of Python! Surely there must be some way to OCR the heck out of this jpg? And, as almost ever, there is a Python solution. Quite quickly I learned there is a Python package called pytesseract that can do OCR.
Using pytesseract for OCR
For a first attempt the code is fairly simple:
import pytesseract
from PIL import Image
im = Image.open("IMG_69EC2B66C329-1.jpeg") # the ROBI image with data
text = pytesseract.image_to_string(im)
print(text)And sure enough, when you run it, you get this result:
83.2 kg 18.7 %
Gewicht Lichaamsvet
Indicator Waarde Standaard
Gewicht 83.2kg Standaard
BMI 23.0 Standaard
Lichaamsvet 18.7% Standaard
Vetmassa 15.6kg Standaard
Vetvrij
lichaamsgewicht 878k
Spiermassa 63.1kg Standaard
Spiersnelheid 75.8% Standaard
Skeletspier 46.5% Standaard
Botmassa 4.5kg Standaard
Eiwitmassa 13.5kg Standaard
Eiwit 16.2% Standaard
Watergewicht 49.6kg Standaard
Lichaamswater 59.6% Standaard
Onderhuids vet 13.4% Standaard
Visceraal vet 5.0 Standaard
BMR 1830kcal
Lichaamsleeftijd 52 Uitstekend
WHR 0.90 StandaardNow all I have to do is select the lines with the data that I want, write it to a cleaned up data output, and I have my data in consumable form.
I got a lot of data out of this. But not all. For example, on this multiline name it would get the text, but value was wrong:

As you can see in the result here:
Vetvrij
lichaamsgewicht 878kIt was probably confused by the value being in the middle of the multiline name?
Also it would not get the text from this part with the human image:

It would not get the numbers here (except the “Standard range”):
Segmentale vetanalyse
Standaardbereik: 80%-160%
Standaard
Standaard \\ Standaard
l R lMaybe that’s something to look into in a later phase.
In any case, I was pretty happy about how easy it was to get the first results. I got enough out of it to start with. Hiding my data in a jpeg is no match for some rudimentary Python skills anymore.
I’ve put my Python code in a Github repository: https://github.com/Marcel-Jan/extract_fitdays_data
Further research
I’ve been thinking how to improve the quality of the results from pytesseract. One approach is to cut parts of the image out, so it can “focus” on these.
But I also read you can do other forms of preprocessing of the image that can help. Like what I read in this post:
https://towardsdatascience.com/getting-started-with-tesseract-part-i-2a6a6b1cf75e
I also want to store my data in a .sqlite database in the future. Now it’s still an Excel sheet. But I could do more in SQL. Maybe make a data warehouse of my own personal data.
To be continued.

3 Comments
Jan · November 9, 2024 at 4:01 pm
Gaaf! Zou je deze weegschaal nog steeds adviseren, of zou je een andere weegschaal kopen (nu je dit weet)?
Marcel-Jan Krijgsman · November 9, 2024 at 8:50 pm
Ik heb niet echt iets om de metingen mee te ijken, maar de variantie van bijvoorbeeld het vetpercentage is een aanzienlijk stuk kleiner. Ik heb meerdere weegschalen in het verleden gehad die een enorme foutenmarge hadden. Dat lijkt nu niet het geval. Voor de rest een prima weegschaal. Hopelijk blijft deze langer goede resultaten leveren.
What I learned from using OCR to get data from my weighing scale | Expedition Data · January 2, 2026 at 11:36 am
[…] bit more than a year ago I wrote about the Robi S11 personal weighing scale and that it would not share its data with me, except as jpeg file (from the Fitdays […]