Installing Hortonworks Data Platform 2.6 on Amazon Web Services (Amazon’s cloud platform), how hard could it be? It’s click, click, next, next, confirm, right?
Well-lll, not quite. Especially if HDP or AWS is new to you. There are many steps and many things to look out for. That’s why I wrote a manual, initially for myself, and here for you.
Disclaimer: This blogpost might change slightly after I’ve gained more experience with my HDP cluster. Most of it works, but I have some problems with a few services. I’ll notify of changes I’ve made at the end of this post.
The cluster
Let’s describe what I’m building here. I want a Hadoop cluster with:
- 1 edge node (that I can access via Interwebs)
- 3 master nodes (or name nodes. This is so that I can try out high availability later)
- 3 workers (or data nodes)
And I want to install various popular modules that will run on Hadoop, like Hive, HBase, Spark and Spark2, Atlas and Ranger.
I chose Ubuntu Server 16.04 as Linux distribution, as it’s in the table of operation support for both HDP 2.6 and Ambari 2.5. (Initially I started with RedHat 7.3 and then discovered that RedHat was not in the OS table of the Ambari 2.5 installation. That was a documentation bug, which Hortonworks has fixed now. RedHat 7 is now supported up to 7.2.)
When I build my cluster, I had access to the AWS environment of my employer, Open Circle Solutions, so I don’t know much about how that process went. I also use an existing Virtual Private Cloud (VPC). Disclaimer: I have some ideas how to set that up, but haven’t tested this.
Launching the edge node
Here I assume you have access to AWS and are able to launch at least one Linux server. Log in AWS and make sure you are in the right district. For me that’s Ireland, but for you that might be.. what ever you favor.
Under AWS Services, go to EC2. You find this in the list under Compute. Click “Launch Instance”. You might be forgiven in thinking that launch means to “start up”. In this case it means to “create”.

Choose Ubuntu Server 16.04 from the Amazon Machine Images:

Select a General purpose instance with type m3.large.

VPC
Go to “Next: Configure Instance Details”. Here we prepare the network settings.

I won’t make a new VPC here, because it will cost my employer extra, but the interface is like this. You get to this window:

Subnet
In my case I created a new subnet for my Hadoop cluster. This is a subnet that you can connect to from the Internet. So probably name it something with “public” in the name.
But what IPv4 CIDR block to choose? Your subnet is part of a VPC. Let’s say you VPC has 100.10.0.0/16 as it’s IPv4 CIDR block. The /16 part tells that the first 16 bits are used for the network ID. The other 16 bits is a range from which you can choose the range of the subnet. 100.10.0.0/16 means all IPs in the VPC start with 100.10. Let’s say you want your subnet to start with 100.10.42. So your IPv4 CIDR block will be 100.10.42.0/24. Again, the /24 part tells that the first 24 bits are decisive for all IPs in the subnet.

Now when you chose to create your VPC or Subnet AWS started a new tab in your browser. Conveniently, there are lots more network-related options in the left hand menu under the VPC dashboard and we need to use them. So keep this second tab open in your browser, so you can switch quickly between creating your instance and changing network settings. Mind you: your launch instance session might time out after a while and AWS will restart from the part where you choose the type of Amazon Machine Image.
Internet gateway
If you don’t have one already, you might also need an Internet gateway. In the VPC dashboard you should see an option called Internet gateways on the left hand side.

Setting one up looks real easy. But then again, there already was one when I started on this Hadoop cluster.

Route tables
Still in the same (“VPC Dashboard”) tab, go to Route Tables.
So, in my case these route tables already existed for the VPC I was working in, but if you have to create it, this is the interface. You just give it a name, probably with “public” in it.

But the next part is very important, Morty. First, since we’re doing this for the edge node and because we’re supposed to access it directly, it needs to be accessible from the Internet gateway. With your route table selected go to the Routes tab below and click Edit. Add a destination 0.0.0.0/0 with as target the id of your Internet gateway.

Now go to the Subnet Associations tab and click Edit. Here place a check mark next to the (public) subnet you want to add.

Security groups
Security groups are the way you place an instance in a certain subnet. They were already created on my environment, but just in case you still have to make them, this is the interface. Put something in the description to show this is the security group with access from the outside world.
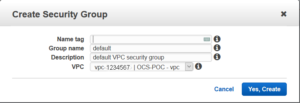
On the security group that is reserved for the edge node it’s a good idea to limit access to it with the inbound rules. With this you can give access to all your colleagues and systems, but not the entire outside world. You can edit that after creating the security group.
Storage
Back to the tab where we were launching the instance. Now we had another HDP cluster with a lot of Hadoop services installed and the edge node raised a warning in Ambari, because the root partition was too full. It turned out to be a real pain to enlarge a root partition. So let’s not get into warnings again. Just give it enough GB’s. Don’t forget to check Delete on termination.

Tags
This is the easy part. Fill in “Name” as key and a good name as value. Tags are not the same as the hostname. They are real easy to change afterwards without restarting anything. You can have several tags with the same name too.

Choose the security group
Pick the security group you created a while back.
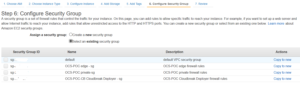
Review
Next it’s review and launch. Check that everything is in order and hit that Launch button.
Key pair
But you’re not done yet. You need to create a key pair (or choose an existing one. But you need to have access to that key!).

Make sure you guard your .pem file (with your key!) with your life!
Now hit Launch Instances.
Work on your instance
You can follow the progress by clicking on the instance id. The instance will be ready within half a minute or so.

Creating a private key
If you want to access your instance with Putty, you need to run PuttyGen to create a private key.

Start PuttyGen and click Load. It shows a list of .ppk files. Put the filter on All files and look for your .pem file (maybe filter by entering *.pem in the File name field, to make finding your keys easier).
Fill in a pass phrase if you need an extra password when connecting to your edge node.
Create and associate an Elastic IP
Your edge node is not accessible yet. It doesn’t have an IP that is accessible from the outside world. That’s where Elastic IPs are for. These Elastic IPs are not free when they’re in use BTW. You’ll find Elastic IP as an option at the left hand menu of both the EC2 and VPC dashboard.
Click Allocate new address to create one. Next select that Elastic IP and associate it with your edge node.

There’s only one Private IP to choose from, namely the IP of the edge node you’re trying to associate.

Log in
Your user to log in on an Ubuntu Server is: ubuntu (RedHat: ec2_user).

You’re the user ubuntu now. You can become root by:
sudo su -
Preparation
You can already generate a key to use for passwordless connections to the other nodes that we will create later. As root, use the command keygen. Don’t give up a pass phrase. Just push enter. The installation of the Ambari cluster won’t work with pass phrases.
You’ll find the keys in /root/.ssh/id_rsa and id_rsa.pub.
Is that all?
No, this is just the edge node. We have way more to do. We’ll create master nodes in a next blogpost.



{kind=link}
2 Comments
Building HDP 2.6 on AWS, Part 2: the master nodes | Expedition Data · May 26, 2017 at 8:48 pm
[…] ← Building HDP 2.6 on AWS, Part 1: the edge node […]
Building HDP 2.6 on AWS, Part 3: the worker nodes | Expedition Data · April 10, 2018 at 2:54 pm
[…] part 3 in a series on how to build a Hortonworks Data Platform 2.6 cluster on AWS. By now we have an edge node to run Ambari Server, three master nodes for Hadoop name nodes and such. Now we need worker nodes […]