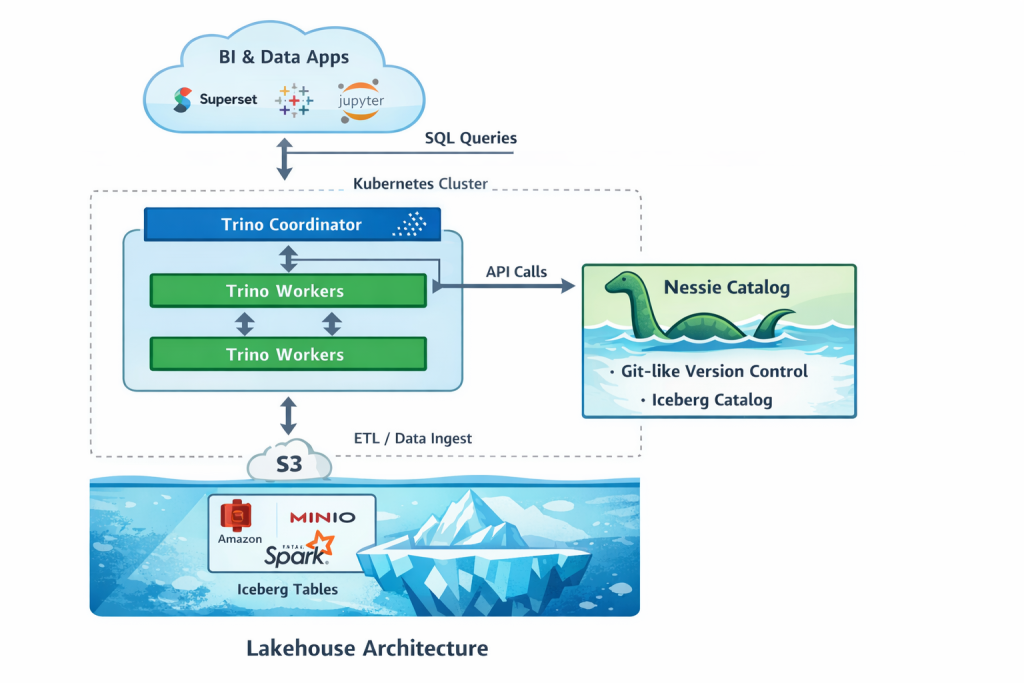
Conferences are a great way to learn diverse topics in your field. That’s why I like to go to events like Pycons and last Friday, PyGrunn. PyGrunn is a Python event in Groningen, the Netherlands. I submitted two talks for the event myself. One of them was selected.
Here is a recap of the talks I attended and the stuff I learned, so you maybe get inspired to attend Python conferences and even speak at these events.
Keeping your Python in check – Mark Boer
Python was originally developed to make coding more accessible. Where at other programming languages you had to tell what type of data type your variables are, Python deduced this automatically. Good for beginning coders, maybe not so good for advanced data solutions.
Mark Boer has experience in strong typing in his data science solutions. He shared how you can ensure typing in different ways: in data classes, using Pydantic and named tuples. The talk assumed that the attendees already had experience with typing. I had not, so it was a lot to take in. But if I can review the video in a few weeks, I hope to catch on.
(more…)