For the third time in a row I’ve attended the ITNEXT Summit. This year I got a ticket from LINKIT, for which I thank them. It was the best ITNEXT Summit I’ve been at so far.
It started with breakfast. I already had it at home, but I can’t resist a good croissant. Mmm… Where was I? Oh yeah, the summit. In this blogpost I look back on the sessions I attended.
Cultivating Production Excellence – Liz Fong-Jones

I’ve been on-call for complex systems in my life, but in the era of containers and serverless things have changed. Some things Liz Fong-Jones spoke about in her keynote did sound familiar, but she discussed how with complex architecures with distributed systems, containers and cloud it is no longer a question of systems being up or down.
In complex systems there is always something down. The question is whether it’s too broken for customers or users. The business and devops need to decide on Service Level Indicators. These indicators tell, in common language what “too broken” means. Together you decide on Service Level Objectives. An example of a SLO: in a window of 30 (or 90 days) events must be “good” (according to business and devops) 99.9% of the time.
You need observability, but it’s more than traces and logs. It needs to go together with Service Level Objectives.
Liz also spoke about “hero culture”: that senior engineer who is the “only one who can solve this” and is therefor always very busy. At some point you need to say to that senior engineer: “you need to document this”, instead of being the hero every time.
Sharing knowledge accross teams – Tara Ojo

Tara Ojo speaks about learning at work
Tara Ojo talked about a topic near and dear to my heart: sharing knowledge in and accross teams. She spoke about how at FutureLearn people are sharing knowledge. One way is by blogging. A good way to deeply learn, is by teaching. So at Futurelearn they have teaching hours. These are sessions of one hour where someone shares something she learned.
To make sure teaching hours aren’t just a flow of information in one direction, the sessions have kind of an agenda. The first 15 minutes there’s a bit of theory, then exercises. And the last 10 minutes are reserved for wrap-up and questions.
They also have “catch-ups” sessions, where a problem one colleague encountered is discussed as a group. And in “talks we love” they watch a video someone liked together in a conference room.
Open Source Code Reviews – Holden Karau

Holden Karau about phrasing in code reviews in open source projects.
Holden’s presentation was so hilarious, that I sometimes forgot to take notes. Sorry about that. But this session is about how many open source projects aren’t limited by the number of coders, but by the number of reviewers. They sometimes really get stuck because of this and the product dies.
So Holden talked about how mermaid school is analogous to doing code review on open source projects. At that time it seemed totally logical, but now I can’t remember exactly how. (But she got her employer to pay for mermaid school partly, so why am I paying the full price for my stage acting lessons? That’s totally necessary to help me grow as a person as well!)
Her take-away is that everyone can do code reviews on open source projects. Yes, you review work of total strangers (who usually work for free). Yes, you need to be a bit more careful in phrasing your review (“Have you looked at X?” instead of “This sucks!”). Actually, that last advice counts not just for open source projects. Just saying.
And sometimes, despite that, you encounter jerks, but the beauty is that there are many, many other projects that need reviewers.
Holden does live code review sessions on Twitch.tv. Oh, and Holden works on a new project “Distributed Systems 4 Kids“. I really like how her brain works. I just can’t wait to see it. Even though I’m not quite a kid anymore.
Debunking Serverless Myths – Yam Cui
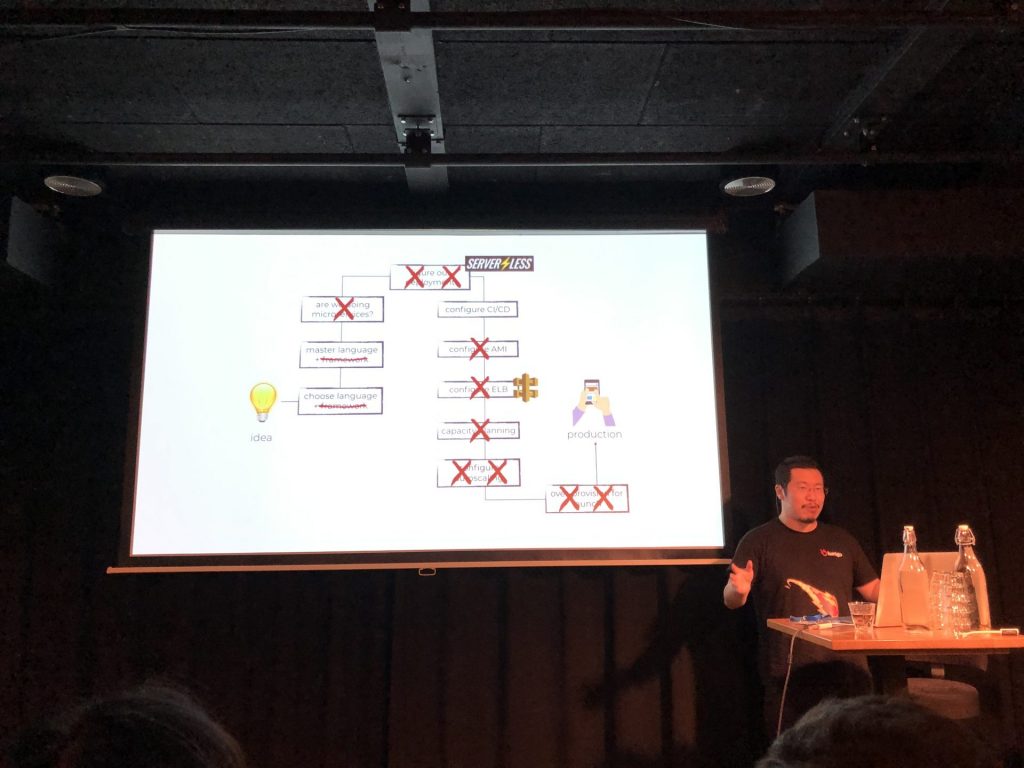
Yam Cui shows how much less work serverless is
Serverless was one of the topics that was on my list for this summit. Yam Cui did a session on serverless myths. He started by discussing what serverless is. It doesn’t mean it runs without servers. “It is serverless the same way that wifi is wireless”.
Serverless works like this: in the old situation, if you wanted to run a certain (application) function, you would create a VM or container, you would install for example Java runtime or Node.js or whatever and then you would install your application. In serverless you can code that (lambda) function (or Function as a Service) and run it in the cloud without installing anything else.
This means no patching, better scalability, better security (out of the box) and better resilience. And: you can go much faster from idea to product. But the biggest advantage is cost reduction. Yam says he experienced 95% lower costs with serverless (in AWS).
However there might be some problems. Because every first time that you run a function, behind the scenes a container is started. That means that the first execute is longer (say 800 ms instead of 80 ms). This is called a cold start. And when you run things distributed, this can mean multiple coldstarts at the same time. That could be a problem in certain cases, mainly when your function experiences peak usage. For example when you are running a food services company (lots of people want their food between 18:00 and 19:00).
Serverless also means giving away control. On the other hand, keeping control means you need more people to build and maintain stuff. But the disadvantage of serverless that people talk the most about, is vendor lock-in. Actually this is not a myth. It’s something you company needs to weigh: much less development and operations cost, or being able to move to a different cloud provider when you want.
Cloud Native Transformations – Pini Reznik

Pini Reznik about the stranger (the disruptor) who comes to town
Pini Reznik took us along a cloud transformation at a hypothetical financial company. At this company it is decided that they need to get to the cloud to keep up with the competition of new fintech disruptors.
In attempt 1 they make this a side project which never gets adequate resources. It fails. In attempt 2 they put half the IT team on a waterfall like cloud transition project. And again they still can’t seem to get this transition going without a lot of delays. So it fails and the CEO tells the IT people its now do or die time. Deliver or else.
Reznik says these transitions often fail, because organizations fail to see the changes that need to be made are on many more levels than just the technical part. Actually this slide explains that the best:

Reznik discussed a couple of tools you can use to make the transition to become cloud native. Number one is the ratio of creativity vs proficiency. In many enterprises there’s 95% of time for delivery, 5% for innovation and 0% for research. But if you want to make that transition to the cloud, you need to take more time for research and innovation.
Take time for exploratory experiments. If successful go on to Proof of Concept’s and work your way to a Minimal Viable Product.
And then there is of course the cultural change. Even in cloud native organizations one thing doesn’t change: you work together towards a shared goal. But there are new ways to achieve that goal. Not just technical ways, but approaches like reflective breaks, learning loops and blameless inquiry.
Make your data FABulous – Philipp Krenn

Philipp Krenn about accuracy on distributed datastores
Philipp Krenn is from Elastic. So when he asked “What is the perfect datastore solution?”, we thought we knew the answer. But the answer is “It depends.” and then it costs a whole lot of money.
He started off with the CAP theorem. CAP stands for:
- Consistent: the total order of operations such that each operation looks like if it were completed in an instant.
- Available: every request received by a non-failing node must result in a response.
- Partition tolerant: the network will be allowed to lose arbitrarily many messages sent from one node to another.
For your distributed systems you can only pick two (although two are not guaranteed). For datastores there’s also FAB:
- Fast: Near real-time instead of batch processing.
- Accurate: Exact instead of accurate results.
- Big: parallellization needed to handle data.
And here you can also only pick two. Now Fast and Big are pretty easy to understand, but what about accurate? Krenn shows that with sharding in ElasticSearch (but not limited to that system), you sometimes get wrong results because of skewed data.
Now at the point he discussed cardinality and LogLog and all that he kind of lost me. So we’ll leave it at that. Still, kudo’s for the live demo in Elastic. His presentation slides can be found here.
Organizing data engineering around Kubeflow – Mátyás Manninger

Mátyás Manninger does a live demo of Kubeflow
Kubeflow is a machine learning toolkit for Kubernetes. It helps you to make and scale machine learning pipelines. Mátyás Manninger showed in a live demo how it works.
Pipelines in Kubeflow are .yaml files (config files), but it also has a GUI with graphical representation. A pipeline has components like: validation, preprocess, training, deployment, prediction and analysis. You can define inputs as arguments or URLs and outputs as local files or URI’s. And there are things called artifacts that can add visualizations.
The pipelines can be reused and shared. You can also use CI/CD tools to deploy this.
Streaming processing beyond streaming data – Stephan Ewen

The spectrum from batch processing to transactional applications
Streaming was high on my list at ITNEXT Summit. And Stephan Ewen had a great session that completely helped me understand how streaming works with Apache Flink. This session alone was worth the price of admission to ITNEXT Summit.
Ewen explained that there is kind of a spectrum on streaming from batch processing to transactional applications. And Apache Flink basically can do that all. Although it’s usually used for streaming. Flink allows streaming analytics, stateful stream processing and event-driven applications. Ewen discussed the first two mostly.
Streaming in your application might look like this:

The Flink streaming API
But for streaming analytics you can also talk SQL to it. Flink allows for batch query execution, like this:
SELECT room,
TUMBLE_END(rowtime, INTERVAL '1' HOUR),
AVG(temperature)
FROM sensors
GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), room
(Sounds interesting for my humidity sensor network at home.)
Flink is also made fault tolerant with checkpoints. When something breaks, you can get back to your stream position by going back to a checkpoint and replaying the data that arrived after that checkpoint.
Everything you don’t want to know about privileged containers – Kris Nova

Kris Nova hacks Kubernetes live on stage
Who says that keynotes always need to be lacklustre, high over presentations by a CEO of a sponsor? Not at ITNEXT Summit. But who expected C code explained in a keynote? Certainly not me. Kris Nova did and, like I already tweeted, I think she did a very admirable job.
https://twitter.com/marceljankr/status/1189596992802033665
She explained the three kernel modules needed to start up a container. It’s surprisingly easy actually. There’s cgroups (control groups) to group processes and tell what their limitations are. Namespaces can make processes appear as if they would be on their own isolated instance. And there’s clone to create a new child process.
Nova created a intrusion detection tool called Falco. It can run as a DaemonSet in Kubernetes to detect intrusions in the cluster. To prove it works, she hacked Kubernetes live on stage. We didn’t get to see what was running in her container called scary, but we did see the detection of what scary did on the cluster. I love demos and presentations like these.
You can find her slides on Github.
The end
And with that and the drinks afterwards ITNEXT Summit was at an end. I think it was the best ITNEXT Summit so far. Great speakers, great talks with fellow attendees and the most useful information for me so far. Congratulations and until next year!
0 Comments